

Sau khi chiếm lĩnh mùa hè với một loạt các mô hình AI ngôn ngữ và mã hóa mã nguồn mở mạnh mẽ, miễn phí, đã sánh ngang hoặc trong một số trường hợp vượt trội so với các đối thủ độc quyền/mã nguồn đóng của Hoa Kỳ, đội ngũ nghiên cứu AI “Qwen Team” xuất sắc của Alibaba hôm nay đã trở lại với việc phát hành một mô hình tạo ảnh AI mới được đánh giá cao — cũng là mã nguồn mở.
Qwen-Image nổi bật trong lĩnh vực đông đúc các mô hình tạo ảnh sinh nhờ vào sự chú trọng của nó vào việc hiển thị văn bản chính xác trong hình ảnh — một lĩnh vực mà nhiều đối thủ vẫn đang gặp khó khăn.
Hỗ trợ cả chữ cái và chữ tượng hình, mô hình đặc biệt thành thạo trong việc quản lý kiểu chữ phức tạp, bố cục nhiều dòng, ngữ nghĩa cấp đoạn văn và nội dung song ngữ (ví dụ: tiếng Anh-tiếng Trung).
Trên thực tế, điều này cho phép người dùng tạo ra nội dung như áp phích phim, trang trình bày, cảnh cửa hàng, thơ viết tay và đồ họa thông tin được cách điệu — với văn bản rõ ràng phù hợp với lời nhắc của họ.
Mở rộng AI chạm giới hạn
Giới hạn năng lượng, chi phí token tăng và độ trễ suy luận đang định hình lại AI doanh nghiệp. Tham gia sự kiện độc quyền của chúng tôi để khám phá cách các đội ngũ hàng đầu đang:
- Biến năng lượng thành lợi thế chiến lược
- Thiết kế suy luận hiệu quả để đạt được thông lượng thực tế
- Mở khóa ROI cạnh tranh với các hệ thống AI bền vững
Đảm bảo chỗ của bạn để luôn dẫn đầu: https://bit.ly/4mwGngO
Các ví dụ đầu ra của Qwen-Image bao gồm nhiều trường hợp sử dụng trong thế giới thực:
- Tiếp thị & Thương hiệu: Áp phích song ngữ với logo thương hiệu, thư pháp cách điệu và họa tiết thiết kế nhất quán
- Thiết kế bài thuyết trình: Bộ slide có nhận thức về bố cục với phân cấp tiêu đề và hình ảnh phù hợp với chủ đề
- Giáo dục: Tạo tài liệu lớp học có biểu đồ và văn bản hướng dẫn được hiển thị chính xác
- Bán lẻ & Thương mại điện tử: Cảnh cửa hàng nơi nhãn sản phẩm, biển hiệu và ngữ cảnh môi trường đều phải dễ đọc
- Nội dung sáng tạo: Thơ viết tay, tường thuật cảnh, minh họa phong cách anime với văn bản câu chuyện nhúng
Người dùng có thể tương tác với mô hình trên trang web Qwen Chat bằng cách chọn chế độ “Tạo ảnh” từ các nút bên dưới trường nhập lời nhắc.
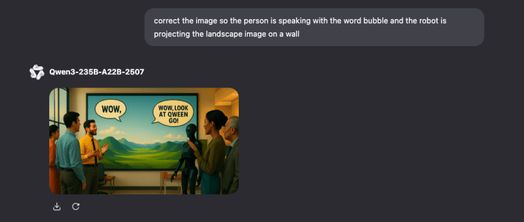
Tuy nhiên, các thử nghiệm ban đầu ngắn gọn của tôi cho thấy độ chính xác của văn bản và sự tuân thủ lời nhắc không tốt hơn đáng kể so với Midjourney, trình tạo ảnh AI độc quyền phổ biến từ công ty cùng tên của Hoa Kỳ. Phiên làm việc của tôi qua Qwen chat đã tạo ra nhiều lỗi trong việc hiểu lời nhắc và độ trung thực của văn bản, khiến tôi rất thất vọng, ngay cả sau nhiều lần thử và thay đổi lời nhắc:

Tuy nhiên, Midjourney chỉ cung cấp một số lượng giới hạn các lần tạo miễn phí và yêu cầu đăng ký để sử dụng thêm, so với Qwen Image, nhờ vào giấy phép mã nguồn mở và trọng số được đăng trên Hugging Face, có thể được áp dụng bởi bất kỳ doanh nghiệp hoặc nhà cung cấp bên thứ ba nào miễn phí.
Cấp phép và khả dụng
Qwen-Image được phân phối theo giấy phép Apache 2.0, cho phép sử dụng thương mại và phi thương mại, phân phối lại và sửa đổi — mặc dù cần phải ghi công và bao gồm văn bản giấy phép đối với các tác phẩm phái sinh.
Điều này có thể khiến nó hấp dẫn đối với các doanh nghiệp đang tìm kiếm một công cụ tạo ảnh mã nguồn mở để sử dụng cho việc tạo các tài liệu nội bộ hoặc bên ngoài như tờ rơi, quảng cáo, thông báo, bản tin và các giao tiếp kỹ thuật số khác.
Nhưng việc dữ liệu huấn luyện của mô hình vẫn là một bí mật được bảo vệ chặt chẽ — giống như hầu hết các trình tạo ảnh AI hàng đầu khác — có thể khiến một số doanh nghiệp không hài lòng với ý tưởng sử dụng nó.
Qwen, không giống như Adobe Firefly hoặc tính năng tạo ảnh gốc của GPT-4o của OpenAI, chẳng hạn, không cung cấp sự bồi thường cho các mục đích sử dụng thương mại sản phẩm của mình (tức là, nếu người dùng bị kiện vì vi phạm bản quyền, Adobe và OpenAI sẽ hỗ trợ họ tại tòa án).
Mô hình và các tài sản liên quan — bao gồm sổ ghi chép demo, công cụ đánh giá và tập lệnh tinh chỉnh — có sẵn thông qua nhiều kho lưu trữ:
Ngoài ra, một cổng đánh giá trực tiếp có tên AI Arena cho phép người dùng so sánh các thế hệ hình ảnh trong các vòng cặp đôi, đóng góp vào bảng xếp hạng công khai kiểu Elo.
Huấn luyện và phát triển
Đằng sau hiệu suất của Qwen-Image là một quá trình huấn luyện mở rộng dựa trên học tập tiến bộ, căn chỉnh tác vụ đa phương thức và quản lý dữ liệu chặt chẽ, theo tài liệu kỹ thuật mà nhóm nghiên cứu đã phát hành hôm nay.
Tập dữ liệu huấn luyện bao gồm hàng tỷ cặp hình ảnh-văn bản được lấy từ bốn lĩnh vực: hình ảnh tự nhiên, chân dung người, nội dung nghệ thuật và thiết kế (như áp phích và bố cục giao diện người dùng), và dữ liệu tổng hợp tập trung vào văn bản. Nhóm Qwen không nêu rõ kích thước của tập dữ liệu huấn luyện, ngoài “hàng tỷ cặp hình ảnh-văn bản.” Họ đã cung cấp một phân tích tỷ lệ phần trăm ước tính của mỗi loại nội dung mà nó bao gồm:
- Tự nhiên: ~55%
- Thiết kế (giao diện người dùng, áp phích, nghệ thuật): ~27%
- Con người (chân dung, hoạt động của con người): ~13%
- Dữ liệu hiển thị văn bản tổng hợp: ~5%
Đáng chú ý, Qwen nhấn mạnh rằng tất cả dữ liệu tổng hợp đều được tạo ra nội bộ, và không có hình ảnh nào được tạo bởi các mô hình AI khác được sử dụng. Mặc dù các giai đoạn quản lý và lọc chi tiết đã được mô tả, tài liệu không làm rõ liệu bất kỳ dữ liệu nào được cấp phép hay được lấy từ các tập dữ liệu công khai hoặc độc quyền.
Không giống như nhiều mô hình tạo sinh loại trừ văn bản tổng hợp do rủi ro nhiễu, Qwen-Image sử dụng các quy trình hiển thị tổng hợp được kiểm soát chặt chẽ để cải thiện phạm vi bao phủ ký tự — đặc biệt đối với các ký tự có tần suất thấp trong tiếng Trung.
Một chiến lược kiểu giáo trình được áp dụng: mô hình bắt đầu với các hình ảnh có chú thích đơn giản và nội dung không phải văn bản, sau đó tiến tới các kịch bản văn bản nhạy cảm với bố cục, hiển thị đa ngôn ngữ và các đoạn văn dày đặc. Việc tiếp xúc dần dần này được chứng minh là giúp mô hình tổng quát hóa trên các kiểu chữ và định dạng.
Qwen-Image tích hợp ba mô-đun chính:
- Qwen2.5-VL, mô hình ngôn ngữ đa phương thức, trích xuất ý nghĩa ngữ cảnh và hướng dẫn tạo sinh thông qua các lời nhắc hệ thống.
- VAE Encoder/Decoder, được huấn luyện trên tài liệu độ phân giải cao và bố cục thực tế, xử lý các biểu diễn hình ảnh chi tiết, đặc biệt là văn bản nhỏ hoặc dày đặc.
- MMDiT, xương sống của mô hình khuếch tán, điều phối việc học chung trên các phương thức hình ảnh và văn bản. Một hệ thống MSRoPE (Mã hóa vị trí quay đa phương thức có khả năng mở rộng) mới lạ giúp cải thiện sự căn chỉnh không gian giữa các token.
Cùng với nhau, các thành phần này cho phép Qwen-Image hoạt động hiệu quả trong các tác vụ liên quan đến hiểu, tạo và chỉnh sửa hình ảnh chính xác.
Các tiêu chuẩn hiệu suất
Qwen-Image đã được đánh giá dựa trên một số tiêu chuẩn công khai:
- GenEval và DPG cho việc tuân thủ lời nhắc và tính nhất quán thuộc tính đối tượng
- OneIG-Bench và TIIF cho lý luận thành phần và độ trung thực bố cục
- CVTG-2K, ChineseWord, và LongText-Bench để hiển thị văn bản, đặc biệt trong các ngữ cảnh đa ngôn ngữ
Trong hầu hết mọi trường hợp, Qwen-Image đều sánh ngang hoặc vượt trội so với các mô hình mã nguồn đóng hiện có như GPT Image 1 [High], Seedream 3.0 và FLUX.1 Kontext [Pro]. Đáng chú ý, hiệu suất của nó trong việc hiển thị văn bản tiếng Trung tốt hơn đáng kể so với tất cả các hệ thống được so sánh.
Trên bảng xếp hạng AI Arena công khai — dựa trên hơn 10.000 so sánh cặp đôi của con người — Qwen-Image xếp thứ ba tổng thể và là mô hình mã nguồn mở hàng đầu.
Ý nghĩa đối với các nhà ra quyết định kỹ thuật doanh nghiệp
Đối với các đội ngũ AI doanh nghiệp quản lý quy trình công việc đa phương thức phức tạp, Qwen-Image mang đến một số lợi thế chức năng phù hợp với nhu cầu vận hành của các vai trò khác nhau.
Những người quản lý vòng đời của các mô hình thị giác-ngôn ngữ — từ huấn luyện đến triển khai — sẽ tìm thấy giá trị trong chất lượng đầu ra nhất quán của Qwen-Image và các thành phần sẵn sàng tích hợp của nó. Tính chất mã nguồn mở giúp giảm chi phí cấp phép, trong khi kiến trúc mô-đun (Qwen2.5-VL + VAE + MMDiT) tạo điều kiện thuận lợi cho việc thích ứng với các tập dữ liệu tùy chỉnh hoặc tinh chỉnh cho các đầu ra cụ thể theo lĩnh vực.
Dữ liệu huấn luyện theo kiểu giáo trình và kết quả tiêu chuẩn rõ ràng giúp các đội đánh giá mức độ phù hợp cho mục đích. Cho dù triển khai hình ảnh tiếp thị, kết xuất tài liệu hay đồ họa sản phẩm thương mại điện tử, Qwen-Image cho phép thử nghiệm nhanh chóng mà không bị ràng buộc độc quyền.
Các kỹ sư được giao nhiệm vụ xây dựng các quy trình AI hoặc triển khai mô hình trên các hệ thống phân tán sẽ đánh giá cao tài liệu cơ sở hạ tầng chi tiết. Mô hình đã được huấn luyện bằng kiến trúc Producer-Consumer, hỗ trợ xử lý đa độ phân giải có thể mở rộng (256p đến 1328p), và được xây dựng để chạy với Megatron-LM và tensor parallelism. Điều này khiến Qwen-Image trở thành một ứng cử viên cho việc triển khai trong môi trường đám mây lai, nơi độ tin cậy và thông lượng là quan trọng.
Hơn nữa, hỗ trợ cho quy trình chỉnh sửa từ hình ảnh sang hình ảnh (TI2I) và lời nhắc cụ thể tác vụ cho phép sử dụng nó trong các ứng dụng thời gian thực hoặc tương tác.
Các chuyên gia tập trung vào việc thu thập, xác thực và chuyển đổi dữ liệu có thể sử dụng Qwen-Image như một công cụ để tạo tập dữ liệu tổng hợp để huấn luyện hoặc tăng cường các mô hình thị giác máy tính. Khả năng tạo ra hình ảnh độ phân giải cao với chú thích nhúng, đa ngôn ngữ của nó có thể cải thiện hiệu suất trong các tác vụ OCR, phát hiện đối tượng hoặc phân tích bố cục tiếp theo.
Vì Qwen-Image cũng được huấn luyện để tránh các hiện tượng như mã QR, văn bản bị méo và hình mờ, nó cung cấp đầu vào tổng hợp chất lượng cao hơn nhiều mô hình công khai — giúp các đội ngũ doanh nghiệp bảo toàn tính toàn vẹn của tập huấn luyện.
Tìm kiếm phản hồi và cơ hội hợp tác
Nhóm Qwen nhấn mạnh sự cởi mở và hợp tác cộng đồng trong việc phát hành mô hình.
Các nhà phát triển được khuyến khích thử nghiệm và tinh chỉnh Qwen-Image, gửi các yêu cầu kéo (pull request) và tham gia bảng xếp hạng đánh giá. Phản hồi về việc hiển thị văn bản, độ trung thực của chỉnh sửa và các trường hợp sử dụng đa ngôn ngữ sẽ định hình các phiên bản tương lai.
Với mục tiêu đã nêu là “hạ thấp các rào cản kỹ thuật trong việc tạo nội dung hình ảnh”, nhóm hy vọng Qwen-Image sẽ không chỉ là một mô hình, mà còn là nền tảng cho nghiên cứu sâu hơn và triển khai thực tế trên các ngành công nghiệp.





