Hướng dẫn về AI đa phương thức: Thị giác, giọng nói, văn bản và hơn thế nữa - KDnuggets
Tin tức AI - 27/01/2026 00:00:00
Các hệ thống AI hiện nay có thể nhìn hình ảnh, nghe giọng nói và xử lý video, hiểu thông tin ở dạng nguyên bản.
Trong nhiều thập kỷ, trí tuệ nhân tạo (AI) đồng nghĩa với văn bản. Bạn nhập một câu hỏi và nhận lại phản hồi bằng văn bản. Ngay cả khi các mô hình ngôn ngữ ngày càng trở nên mạnh mẽ hơn, giao diện vẫn không thay đổi: một khung văn bản chờ đợi những câu lệnh (prompt) được soạn thảo kỹ lưỡng của bạn.
Điều đó đang thay đổi. Các hệ thống AI mạnh mẽ nhất hiện nay không chỉ biết đọc. Chúng nhìn thấy hình ảnh, nghe thấy tiếng nói, xử lý video và hiểu dữ liệu có cấu trúc. Đây không phải là sự tiến bộ từng bước; đó là một sự thay đổi cơ bản trong cách chúng ta tương tác và xây dựng các ứng dụng AI.
Chào mừng bạn đến với AI đa phương thức (multimodal AI).
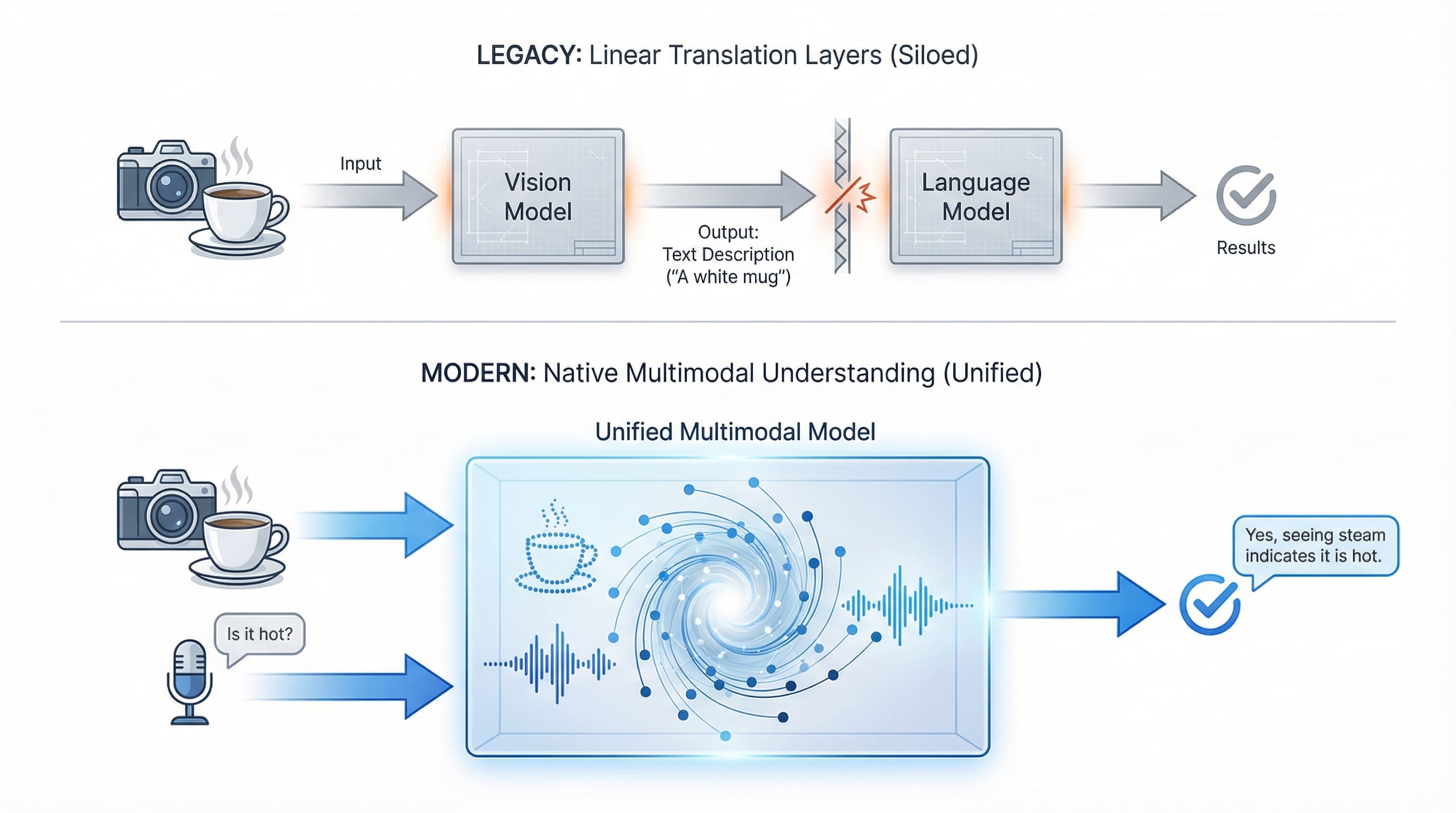
Tác động thực sự không chỉ là việc các mô hình có thể xử lý nhiều loại dữ liệu hơn. Đó là việc toàn bộ quy trình làm việc đang được rút gọn. Các tác vụ từng đòi hỏi nhiều bước chuyển đổi — từ hình ảnh sang mô tả văn bản, từ giọng nói sang bản ghi âm, từ sơ đồ sang giải thích — giờ đây diễn ra trực tiếp. AI hiểu thông tin ở dạng nguyên bản, loại bỏ lớp chuyển đổi vốn đã định hình sự tương tác giữa người và máy tính trong nhiều thập kỷ.
AI đa phương thức đề cập đến các hệ thống có thể xử lý và tạo ra nhiều loại dữ liệu (phương thức) cùng một lúc. Điều này không chỉ bao gồm văn bản mà còn cả hình ảnh, âm thanh, video và ngày càng tăng là dữ liệu không gian 3D, cơ sở dữ liệu có cấu trúc và các định dạng chuyên biệt như cấu trúc phân tử hoặc ký hiệu âm nhạc.
Bước đột phá không chỉ nằm ở việc làm cho các mô hình lớn hơn. Đó là việc học cách biểu diễn các loại dữ liệu khác nhau trong một "không gian hiểu biết" chung, nơi chúng có thể tương tác với nhau. Một hình ảnh và chú thích của nó không phải là những thứ tách biệt tình cờ có liên quan; chúng là những cách thể hiện khác nhau của cùng một khái niệm cơ bản, được ánh xạ vào một biểu diễn chung.
Điều này tạo ra những khả năng mà các hệ thống đơn phương thức không thể đạt được. Một AI chỉ có văn bản có thể mô tả một bức ảnh nếu bạn giải thích bằng lời. Một AI đa phương thức có thể nhìn thấy bức ảnh và hiểu được bối cảnh mà bạn chưa bao giờ đề cập đến: ánh sáng, cảm xúc trên khuôn mặt, mối quan hệ không gian giữa các vật thể. Nó không chỉ xử lý nhiều đầu vào; nó tổng hợp sự hiểu biết thông qua chúng.
Sự khác biệt giữa các mô hình "thực sự đa phương thức" và "hệ thống đa phương thức" là rất quan trọng. Một số mô hình xử lý mọi thứ cùng nhau trong một kiến trúc thống nhất. GPT-4 Vision (GPT-4V) nhìn và hiểu đồng thời. Những mô hình khác kết nối các mô hình chuyên biệt: một mô hình thị giác phân tích hình ảnh, sau đó chuyển kết quả cho một mô hình ngôn ngữ để suy luận. Cả hai phương pháp đều hiệu quả. Phương pháp đầu tiên mang lại sự tích hợp chặt chẽ hơn, trong khi phương pháp sau mang lại sự linh hoạt và chuyên môn hóa cao hơn.
Ba phương thức này đã đủ chín muồi để sử dụng rộng rãi trong thực tế, mỗi phương thức mang lại những khả năng và các ràng buộc kỹ thuật riêng biệt cho các hệ thống AI.
AI thị giác đã phát triển từ phân loại hình ảnh cơ bản sang hiểu biết thị giác thực sự. GPT-4V và Claude có thể phân tích biểu đồ, sửa lỗi mã nguồn từ ảnh chụp màn hình và hiểu bối cảnh thị giác phức tạp. Gemini tích hợp thị giác một cách tự nhiên trên toàn bộ giao diện của nó. Các lựa chọn thay thế mã nguồn mở — LLaVA, Qwen-VL và CogVLM — hiện đã sánh ngang với các tùy chọn thương mại trong nhiều tác vụ trong khi vẫn chạy được trên phần cứng tiêu dùng.
Đây là nơi sự thay đổi quy trình làm việc trở nên rõ ràng: thay vì mô tả những gì bạn thấy trong ảnh chụp màn hình hoặc sao chép dữ liệu biểu đồ một cách thủ công, bạn chỉ cần đưa nó ra. AI sẽ thấy trực tiếp. Những gì trước đây mất năm phút mô tả cẩn thận thì giờ đây chỉ mất năm giây tải lên.
Tuy nhiên, thực tế kỹ thuật lại đặt ra những hạn chế. Bạn thường không thể truyền trực tiếp video thô 60 khung hình/giây (fps) đến một mô hình ngôn ngữ lớn (LLM). Việc đó quá chậm và tốn kém. Các hệ thống thực tế sử dụng kỹ thuật **lấy mẫu khung hình (frame sampling)**, trích xuất các khung hình chính (có lẽ là hai giây một lần) hoặc triển khai các mô hình "phát hiện thay đổi" nhẹ để chỉ gửi các khung hình khi cảnh quan thị giác thay đổi.
Điều làm cho thị giác trở nên mạnh mẽ không chỉ là việc nhận dạng các vật thể. Đó là suy luận không gian: hiểu rằng chiếc cốc đang ở trên bàn chứ không phải đang lơ lửng. Đó là đọc thông tin ẩn ý: nhận ra rằng một chiếc bàn bừa bộn gợi ý sự căng thẳng, hoặc xu hướng của một biểu đồ mâu thuẫn với văn bản đi kèm. AI thị giác xuất sắc trong việc phân tích tài liệu, gỡ lỗi thị giác, tạo hình ảnh và bất kỳ tác vụ nào áp dụng nguyên tắc "trực quan sinh động".
AI giọng nói mở rộng ra ngoài việc chuyển âm đơn giản. Whisper đã thay đổi lĩnh vực này bằng cách cung cấp khả năng nhận dạng giọng nói chất lượng cao miễn phí và cục bộ. Nó xử lý các giọng địa phương, tiếng ồn nền và âm thanh đa ngôn ngữ với độ tin cậy đáng kinh ngạc. Nhưng AI giọng nói hiện nay còn bao gồm chuyển văn bản thành giọng nói (TTS) thông qua ElevenLabs, Bark, hoặc Coqui, cùng với khả năng phát hiện cảm xúc và nhận dạng người nói.
Giọng nói phá vỡ một nút thắt cổ chai chuyển đổi khác: bạn nói một cách tự nhiên thay vì gõ ra những gì bạn định nói. AI nghe thấy giọng điệu của bạn, nắm bắt được sự do dự của bạn và phản hồi những gì bạn muốn truyền đạt, chứ không chỉ là những từ ngữ mà bạn cố gắng gõ ra.
Thách thức hàng đầu hiện nay không phải là chất lượng bản ghi; đó là độ trễ và việc luân phiên lượt nói. Trong một cuộc hội thoại thời gian thực, việc chờ đợi ba giây để nhận phản hồi cảm thấy không tự nhiên. Các kỹ sư giải quyết vấn đề này bằng **phát hiện hoạt động giọng nói (VAD)**, các thuật toán phát hiện chính xác mili giây người dùng ngừng nói để kích hoạt mô hình ngay lập tức, cùng với hỗ trợ "nói chen ngang" cho phép người dùng ngắt lời AI giữa lúc nó đang phản hồi.
Sự khác biệt giữa chuyển âm và thấu hiểu là rất quan trọng. Whisper chuyển đổi lời nói thành văn bản với độ chính xác ấn tượng. Tuy nhiên, các mô hình giọng nói mới hơn có thể nắm bắt được tông giọng, phát hiện sự châm biếm, nhận diện sự do dự và hiểu bối cảnh mà chỉ riêng văn bản sẽ bỏ lỡ. Một khách hàng nói "được thôi" với sự bực bội sẽ khác với "được thôi" với sự hài lòng. AI giọng nói nắm bắt được sự khác biệt đó.
Tích hợp văn bản đóng vai trò là chất keo gắn kết mọi thứ lại với nhau. Các mô hình ngôn ngữ cung cấp khả năng suy luận, tổng hợp và tạo nội dung mà các phương thức khác còn thiếu. Một mô hình thị giác có thể nhận dạng các vật thể trong một hình ảnh; một LLM giải thích ý nghĩa của chúng. Một mô hình âm thanh có thể ghi lại lời nói; một LLM trích xuất thông tin chi tiết từ cuộc trò chuyện.
Khả năng này đến từ sự kết hợp. Hãy cho AI xem một bản quét y tế trong khi mô tả các triệu chứng, và nó sẽ tổng hợp sự hiểu biết qua các phương thức. Điều này vượt xa việc xử lý song song; đó là suy luận đa giác quan thực sự, nơi mỗi phương thức cung cấp thông tin để diễn giải những phương thức khác.
Trong khi thị giác, giọng nói và văn bản đang chiếm lĩnh các ứng dụng hiện tại, bối cảnh đa phương thức đang mở rộng nhanh chóng.
Hiểu biết không gian và 3D đưa AI vượt ra ngoài những hình ảnh phẳng vào không gian vật lý. Các mô hình nắm bắt được chiều sâu, các mối quan hệ ba chiều và suy luận không gian cho phép ứng dụng vào robot, thực tế tăng cường (AR), thực tế ảo (VR) và các công cụ kiến trúc. Các hệ thống này hiểu rằng một chiếc ghế được nhìn từ các góc độ khác nhau vẫn là cùng một vật thể.
Dữ liệu có cấu trúc dưới dạng một phương thức đại diện cho một bước tiến tinh tế nhưng quan trọng. Thay vì chuyển đổi bảng tính thành văn bản cho các LLM, các hệ thống mới hơn hiểu các bảng, cơ sở dữ liệu và biểu đồ một cách nguyên bản. Chúng nhận ra rằng một cột đại diện cho một danh mục, rằng mối quan hệ giữa các bảng mang ý nghĩa và dữ liệu chuỗi thời gian có các mẫu thời gian. Điều này cho phép AI truy vấn trực tiếp cơ sở dữ liệu, phân tích các báo cáo tài chính mà không cần gợi ý và suy luận về thông tin có cấu trúc mà không bị mất dữ liệu khi chuyển đổi sang văn bản.
Khi AI hiểu các định dạng gốc, những khả năng hoàn toàn mới sẽ xuất hiện. Một nhà phân tích tài chính có thể chỉ vào một bảng tính và hỏi "tại sao doanh thu giảm trong quý 3?". AI đọc cấu trúc bảng, phát hiện điểm bất thường và giải thích nó. Một kiến trúc sư có thể đưa vào các mô hình 3D và nhận phản hồi về không gian mà không cần chuyển đổi mọi thứ thành sơ đồ 2D trước.
Các phương thức chuyên biệt theo lĩnh vực hướng tới các lĩnh vực cụ thể. Khả năng hiểu cấu trúc protein của AlphaFold đã mở ra cơ hội tìm kiếm thuốc cho AI. Các mô hình hiểu ký hiệu âm nhạc cho phép tạo ra các công cụ sáng tác. Các hệ thống xử lý dữ liệu cảm biến và thông tin chuỗi thời gian đưa AI vào Internet vạn vật (IoT) và giám sát công nghiệp.
AI đa phương thức đã rời khỏi các bài báo nghiên cứu để đi vào các hệ thống thực tế giải quyết các vấn đề thực tế.
Sự chuyển đổi thể hiện ở cách mọi người làm việc: thay vì chuyển đổi qua lại giữa các công cụ, bạn chỉ cần đưa ra và hỏi. Sự cản trở biến mất. Các phương pháp tiếp cận đa phương thức cho phép mỗi loại thông tin được giữ nguyên ở dạng nguyên bản của nó.
Thách thức trong thực tế thường ít nằm ở khả năng mà nằm nhiều hơn ở độ trễ. Các hệ thống chuyển đổi từ giọng nói sang giọng nói phải xử lý âm thanh → văn bản → suy luận → văn bản → âm thanh trong vòng chưa đầy 500 mili giây để tạo cảm giác tự nhiên, đòi hỏi các kiến trúc truyền phát (streaming) xử lý dữ liệu theo từng đoạn.
A mới infrastructure lớp đang hình thành xung quanh sự phát triển đa phương thức:
Hạ tầng đang dân chủ hóa AI đa phương thức. Những gì đòi hỏi các nhóm nghiên cứu từ nhiều năm trước giờ đây có thể chạy trong mã của các khung làm việc (framework). Những gì từng tốn hàng ngàn đô la phí API giờ đây chạy cục bộ trên phần cứng tiêu dùng.
AI đa phương thức đại diện cho nhiều thứ hơn là chỉ khả năng kỹ thuật; nó đang thay đổi cách con người và máy tính tương tác. Giao diện người dùng đồ họa (GUI) đang nhường chỗ cho các giao diện đa phương thức, nơi bạn trình bày, nói, vẽ và trò chuyện một cách tự nhiên.
Điều này cho phép các kiểu tương tác mới như **nêu thực tế thị giác (visual grounding)**. Thay vì gõ "vật thể màu đỏ ở góc đó là gì?", người dùng vẽ một vòng tròn trên màn hình của họ và hỏi "đây là cái gì?". AI nhận được cả tọa độ hình ảnh và văn bản, gắn kết ngôn ngữ vào các điểm ảnh thị giác.
Tương lai của AI không phải là lựa chọn giữa thị giác, giọng nói hay văn bản. Đó là xây dựng các hệ thống hiểu cả ba phương thức đó một cách tự nhiên như con người vẫn làm.
Vinod Chugani là một nhà giáo dục về AI và khoa học dữ liệu, người thu hẹp khoảng cách giữa các công nghệ AI mới nổi và ứng dụng thực tế cho các chuyên gia đang làm việc. Các lĩnh vực tập trung của ông bao gồm AI tác tử (agentic AI), các ứng dụng học máy và quy trình tự động hóa. Thông qua công việc là một người cố vấn kỹ thuật và giảng viên, Vinod đã hỗ trợ các chuyên gia dữ liệu thông qua phát triển kỹ năng và chuyển đổi nghề nghiệp. Ông mang lại chuyên môn phân tích từ tài chính định lượng vào phương pháp giảng dạy thực hành của mình. Nội dung của ông nhấn mạnh vào các chiến lược và khung làm việc có thể thực hiện được mà các chuyên gia có thể áp dụng ngay lập tức.






