Bộ nhớ có điều kiện Engram của DeepSeek cho thấy cách giảm lãng phí tính toán AI
Tin tức AI - 20/01/2026 20:44:22
Mô hình AI Engram mới của DeepSeek tách biệt việc truy xuất và suy luận bằng bộ nhớ dựa trên mã băm trong RAM, giảm áp lực lên GPU để các đội ngũ có thể chạy các mô hình nhanh hơn với chi phí thấp hơn.
Liệu transformer có thực sự là đỉnh cao của sự đổi mới AI, hay chúng chỉ là một cách thức được thiết kế quá mức để giải quyết các vấn đề đơn giản? Prompt Engineering khám phá cách DeepSeek Engram đổi mới thách thức sự thống trị của các kiến trúc dựa trên transformer bằng cách đề xuất một giải pháp thay thế táo bạo: coi transformer không khác gì những bảng băm đắt tiền. Tuyên bố đầy khiêu khích này bắt nguồn từ khả năng của Engram trong việc tách biệt các nhiệm vụ truy xuất đơn giản khỏi khả năng suy luận phức tạp, giới thiệu một cách thông minh và hiệu quả hơn để xử lý tính toán mô hình ngôn ngữ. Bằng cách tư duy lại cách xử lý các nhiệm vụ, Engram không chỉ giảm lãng phí tính toán mà còn định nghĩa lại khả năng mở rộng và tốc độ trong các mô hình ngôn ngữ lớn.
Trong bài tổng quan này, chúng tôi sẽ phân tích những đổi mới cốt lõi đằng sau Engram, bao gồm việc sử dụng tra cứu dựa trên mã băm cho các nhiệm vụ bộ nhớ đơn giản và cơ chế cổng nhận biết ngữ cảnh để suy luận sâu hơn. Bạn sẽ khám phá cách kiến trúc này giảm thiểu tải cho GPU, cải thiện độ trễ và thách thức sự kém hiệu quả của các transformer truyền thống. Nhưng không phải mọi thứ đều suôn sẻ, việc Engram phụ thuộc vào các bảng tra cứu tĩnh và khả năng xung đột mã băm đặt ra những câu hỏi quan trọng về khả năng thích ứng và độ chính xác của nó. Liệu đây có phải là tương lai của AI, hay chỉ là một bước đệm cho điều gì đó lớn lao hơn? Hãy cùng khám phá những tác động và hạn chế của phương pháp mới này.
Tóm tắt các điểm chính:
Các transformer, kiến trúc nền tảng đằng sau nhiều LLM, áp dụng cùng một nỗ lực tính toán cho mọi nhiệm vụ, bất kể độ phức tạp. Dù là truy xuất một sự thật đơn giản như "Paris là thủ đô của Pháp" hay giải quyết một vấn đề suy luận thách thức, các transformer đều xử lý các nhiệm vụ này như nhau. Cách tiếp cận đồng nhất này dẫn đến sự kém hiệu quả: các nhiệm vụ truy xuất đơn giản lại huy động nhiều lớp transformer một cách không cần thiết, làm tăng chi phí tính toán và hạn chế khả năng mở rộng. Khi các LLM ngày càng lớn và phức tạp hơn, những sự kém hiệu quả này ngày càng trở nên rắc rối, cản trở khả năng hoạt động hiệu quả của chúng trong các kịch bản thực tế.
Engram giới thiệu một kiến trúc mới giải quyết những vấn đề kém hiệu quả này bằng cách tích hợp cơ chế bộ nhớ có điều kiện. Cơ chế này tách biệt các nhiệm vụ bộ nhớ tĩnh, chẳng hạn như truy xuất sự thật, khỏi các nhiệm vụ suy luận động đòi hỏi tính toán sâu hơn. Các thành phần chính của hệ thống này bao gồm:
Bằng cách phân bổ tài nguyên tính toán dựa trên độ phức tạp của nhiệm vụ, Engram đạt được sự cân bằng giữa tốc độ và độ chính xác, biến nó thành một giải pháp thay thế hiệu quả hơn cho các mô hình dựa trên transformer truyền thống.
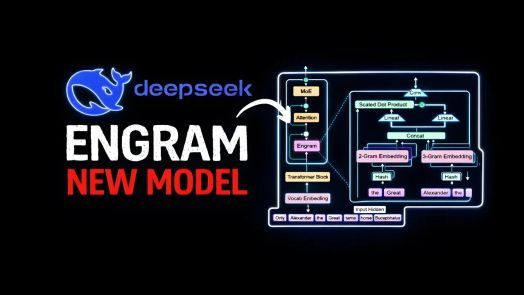
Kiến trúc của Engram sử dụng các tổ hợp token, hay n-gram, được trích xuất từ văn bản đầu vào để tối ưu hóa việc xử lý nhiệm vụ. Các n-gram này được băm để truy xuất các embedding từ một bảng tra cứu đã được huấn luyện trước được lưu trữ trong RAM hệ thống. Quá trình diễn ra như sau:
Thiết kế này đẩy các nhiệm vụ bộ nhớ tĩnh sang tra cứu dựa trên mã băm, giải phóng các lớp transformer cho các nhiệm vụ đòi hỏi suy luận sâu hơn. Bằng cách giảm gánh nặng tính toán lên các transformer, Engram không chỉ cải thiện hiệu quả mà còn giảm thiểu độ trễ trong quá trình suy luận, cho phép hiệu suất nhanh hơn và phản hồi tốt hơn.
Engram mang lại những cải thiện hiệu suất đáng kể trên nhiều tiêu chuẩn khác nhau, chứng minh hiệu quả của nó trong việc tối ưu hóa tính toán LLM. Các lĩnh vực cải thiện chính bao gồm:
Bằng cách phân bổ lại tài nguyên để tập trung vào suy luận phức tạp, Engram cho phép xử lý sâu hơn và chính xác hơn mà không cần tăng số lượng các lớp transformer. Điều này dẫn đến việc hoàn thành nhiệm vụ nhanh hơn và khả năng mở rộng được cải thiện, biến nó thành một giải pháp thực tế cho các ứng dụng quy mô lớn.
Việc Engram phụ thuộc vào tra cứu dựa trên mã băm mang lại một số tối ưu hóa phần cứng giúp nó dễ tiếp cận và tiết kiệm chi phí triển khai hơn. Chúng bao gồm:
Những hiệu quả phần cứng này hạ thấp rào cản trong việc triển khai các LLM quy mô lớn, cho phép các tổ chức sử dụng các khả năng AI tiên tiến mà không phải chịu chi phí quá cao. Điều này khiến Engram đặc biệt hấp dẫn đối với các ngành công nghiệp yêu cầu các giải pháp AI có thể mở rộng và hiệu quả.
Mặc dù Engram mang lại nhiều lợi thế, nhưng nó không phải là không có những thách thức. Một số hạn chế chính bao gồm:
Những hạn chế này nhấn mạnh các lĩnh vực mà nghiên cứu và phát triển bổ sung có thể nâng cao khả năng của Engram, đảm bảo tính ứng dụng của nó trên phạm vi trường hợp sử dụng rộng lớn hơn.
Thiết kế của Engram lấy cảm hứng từ nhận thức của con người, phản ánh sự tách biệt giữa truy xuất tự động, nhanh chóng (Hệ thống 1) và suy luận có chủ đích, nỗ lực (Hệ thống 2). Phương pháp này đại diện cho một sự phát triển đáng kể trong kiến trúc LLM, tương tự như việc giới thiệu các cơ chế chú ý trong các mô hình trước đây. Bằng cách điều chỉnh các phương pháp tính toán phù hợp với yêu cầu nhiệm vụ, Engram giảm chi phí và cải thiện khả năng mở rộng, giúp AI tiên tiến trở nên dễ tiếp cận hơn với nhiều đối tượng hơn. Tầm ảnh hưởng của nó có thể mở rộng ra ngoài LLM, định hình những đổi mới tương lai trong AI bằng cách nhấn mạnh vào hiệu quả, xử lý theo nhiệm vụ cụ thể và tối ưu hóa tài nguyên.






