AI mới của Adobe tập trung hoàn toàn vào âm thanh. Cách tạo nhạc cho video của bạn với Firefly
Tin tức AI - 30/10/2025 23:00:04
Đây là cách bạn có thể sử dụng mô hình nhạc AI của Adobe để tạo nhạc nền cho tất cả các video của mình.

Phần lớn tin tức và cập nhật sản phẩm mà Adobe công bố trong tuần này, không ngạc nhiên, là tập trung vào AI tạo sinh. Nhưng trong khi phần lớn năm nay đã chứng kiến những bước tiến lớn trong việc tạo hình ảnh và video, Adobe đang tập trung nâng cao các sản phẩm AI của mình ở một lĩnh vực khác: AI âm thanh.
Hai tính năng mới, tạo nhạc nền (generate soundtrack) và tạo giọng nói (generate speech), thực hiện chính xác như tên gọi của chúng. Bạn có thể tạo nhạc nền và ghi lại kịch bản cho video của mình. Nhưng mỗi tính năng đều đi kèm với các điều khiển trực quan giúp AI âm thanh không còn là một sự may rủi mà trở thành một công cụ hữu ích cho những người sáng tạo ở mọi cấp độ kỹ năng. Chúng hiện đã có sẵn ở phiên bản beta.
Adobe cũng đang phát hành phiên bản beta của mô hình hình ảnh Firefly thế hệ thứ năm mới nhất của mình. Nó hứa hẹn sẽ tốt hơn trong việc tạo ra hình ảnh chân thực, và giờ đây bạn có thể sử dụng tính năng chỉnh sửa dựa trên câu lệnh. Ngoài ra còn có một trình chỉnh sửa video Firefly beta mới đi kèm với dòng thời gian đa rãnh nhằm giúp bạn biên soạn các clip do AI tạo ra. Adobe cũng đang mở rộng quan hệ đối tác với hai công ty AI mới là ElevenLabs và Topaz Labs. Để biết thêm tin tức về AI, bạn có thể tìm hiểu về các trợ lý AI sắp có mặt trong Photoshop và Express.

Đây là một ví dụ về cách bạn được nhắc để viết mô tả nhạc AI của mình. Adobe
Cấp phép âm nhạc rất phức tạp, đặc biệt là đối với mục đích thương mại. Vì vậy, hãy để tôi bắt đầu với phần quan trọng nhất: Bất kỳ bản nhạc nào được tạo bằng tính năng tạo nhạc nền của Firefly đều được cấp phép phổ quát, có nghĩa là bạn có thể sử dụng nó cho bất kỳ mục đích nào, vô thời hạn. Adobe tạo các công cụ AI của mình bằng cách sử dụng nội dung (trong trường hợp này là âm thanh) mà họ có quyền sử dụng để đào tạo AI. Vì vậy, về lý thuyết, bạn sẽ không bị xóa âm thanh AI của Firefly khỏi YouTube hoặc các nền tảng khác hay nhận cảnh cáo vi phạm bản quyền đáng sợ.
"Đây là thời điểm độc đáo trên thế giới khi cấp phép âm nhạc là mối quan tâm hàng đầu của mọi người và những người sáng tạo đang bực bội vì họ cố gắng làm điều tốt nhất cho nội dung của mình, hoặc họ bối rối," Jay LeBoeuf, trưởng bộ phận AI âm thanh của Adobe, cho biết trong một cuộc phỏng vấn. "Vì vậy, chúng tôi chỉ hy vọng loại bỏ sự nhầm lẫn."
Trong một bản demo, Firefly đã từ chối một câu lệnh có tên của một nghệ sĩ vì nó vi phạm nguyên tắc người dùng do lo ngại về bản quyền. Ví dụ, vì mô hình không được đào tạo trên âm nhạc của Taylor Swift, nên nó không thể tạo ra nhạc tương tự của cô ấy.
Bây giờ, đến phần thú vị: Tạo nhạc nền (Generate soundtrack) là công cụ nhạc AI đầu tiên của Adobe, và nó được thiết kế để loại bỏ mọi phỏng đoán về những gì bạn muốn. Bạn tải video của mình lên, và AI sẽ phân tích nó. Dựa trên đánh giá của nó, Firefly sẽ viết một câu lệnh mà nó cho là có thể hoạt động tốt cho video của bạn. Đó là một câu lệnh kiểu Mad Libs, và bạn có thể thay đổi các mô tả theo ý mình. Câu lệnh có ba phần: mô tả cảm giác chung, phong cách (hãy nghĩ đến thể loại) và mục đích (thương mại, thử nghiệm, v.v.). Bạn cũng có thể điều chỉnh nhịp độ và mức năng lượng.
Khi bạn hài lòng với câu lệnh của mình, hãy nhấp vào tạo và chưa đầy hai phút sau, bốn biến thể chỉ có nhạc cụ sẽ sẵn sàng để bạn phát. Âm thanh của bạn sẽ có độ dài bằng video của bạn, nhưng bạn có thể chỉnh sửa nó nếu cần. Bạn có thể tải lên các video dài tối đa năm phút.
Giờ đây bạn có thể thử tự tạo nhạc cụ AI cho video của mình. Tạo nhạc nền và tạo giọng nói đều có sẵn thông qua Firefly, và chúng đang ở phiên bản beta. Kiểm tra xem gói Adobe của bạn có bao gồm quyền truy cập Firefly không, và nếu không, bạn có thể mua một gói bắt đầu từ 10 đô la mỗi tháng.
Khi bạn có một bản nhạc nền ưng ý, bạn có thể tải toàn bộ video (hoặc chỉ bản nhạc nền) về máy tính của mình.
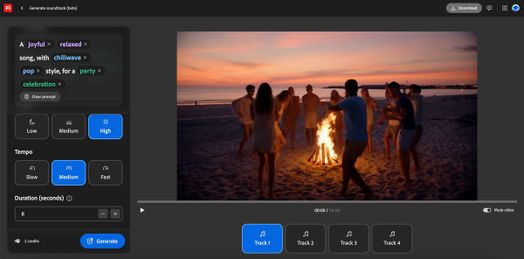
Đây là một ví dụ về bốn bản nhạc nền mà Firefly đã tạo cho một video AI tôi làm về một số người đang tiệc tùng trên bãi biển. Ảnh chụp màn hình của Katelyn Chedraoui/CNET
Tạo giọng nói trong Firefly rất đơn giản, và nó bao gồm nhiều tính năng sẽ làm cho nó hữu ích cho hầu hết mọi dự án. Đó là một cửa sổ đơn giản nơi bạn có thể nhập các từ mà bạn muốn giọng nói AI đọc. Bạn cũng có thể tải lên một kịch bản tối đa 7.500 ký tự – tương đương một video dài 15 đến 20 phút. Sau khi tải lên, bạn có thể chọn từ 50 giọng nói, mỗi giọng được gắn thẻ với độ tuổi và giới tính gần đúng, bao gồm cả các lựa chọn phi nhị phân. Bạn có thể tạo giọng nói bằng 20 ngôn ngữ khác nhau. Nhưng phần thú vị là những gì bạn có thể làm để tinh chỉnh câu lệnh của mình.
Giọng nói không chỉ đơn thuần là đọc chữ trên trang giấy. Khi chúng ta đọc những đoạn văn dài hoặc nói chuyện với người khác, chúng ta tự nhiên thêm trọng âm, cảm xúc và nhịp điệu vào lời nói của mình. Với chương trình mới, bạn có thể làm điều tương tự, thêm các khoảng dừng nơi bạn muốn AI nghỉ ngơi và làm nổi bật các phần mà giọng điệu nên thay đổi.
Nếu bạn giống tôi và không ai phát âm tên bạn đúng ngay từ lần đầu tiên, bạn có thể sử dụng công cụ "sửa lỗi phát âm" để đảm bảo không có lỗi nào. Chọn tên riêng hoặc danh từ riêng rồi thêm phân tích ngữ âm, và AI sẽ sử dụng điều đó để làm cho cách phát âm mượt mà hơn.
Những công cụ này, cùng với khả năng điều chỉnh các phần cụ thể của bạn, nhằm mang lại cho bạn nhiều quyền kiểm soát hơn, điều mà các chương trình chuyển văn bản thành giọng nói khác không phải lúc nào cũng cung cấp.
"Đây là một cách để chúng tôi cung cấp giọng nói giống như thật cho những người sáng tạo, chủ doanh nghiệp nhỏ, nhà giáo dục, cho tất cả những ai thực sự có một câu chuyện để kể, và có lẽ họ không thoải mái như chúng tôi khi chỉ cần lấy mic ra và nói," LeBoeuf nói.
Firefly audio là một mô hình AI hoàn toàn mới. Nhưng đó không phải là lựa chọn duy nhất của bạn. Adobe đã liên tục bổ sung các mô hình AI của bên thứ ba vào danh sách của mình trong năm nay, cho cả video và hình ảnh AI. Họ đang mở rộng các lựa chọn đó một lần nữa bằng cách đưa mô hình đa ngôn ngữ V2 của ElevenLabs vào làm một lựa chọn để tạo giọng nói.






