5 bài học AI trong Excel tôi học được qua những trải nghiệm xương máu
Tin tức AI - 26/11/2025 07:00:00
Bài viết này biến những trải nghiệm không mong muốn thành năm khuôn khổ toàn diện sẽ nâng cao công việc học máy dựa trên Excel của bạn.

Đối với nhiều tổ chức, đặc biệt là những tổ chức trong các ngành được quản lý hoặc có hạ tầng kỹ thuật hạn chế, Excel và tiện ích bổ sung XLMiner của nó đóng vai trò là nền tảng chính cho các quy trình mô hình hóa dự đoán và học máy.
Tuy nhiên, tính dễ tiếp cận của Excel che giấu một khoảng trống quan trọng: sự khác biệt giữa việc chạy mô hình và xây dựng các hệ thống phân tích đáng tin cậy. Khi thực hiện một dự án dự đoán phê duyệt khoản vay, tôi nhận thấy rằng học máy dựa trên Excel thất bại không phải do các hạn chế thuật toán, mà do một số thực hành thường bị bỏ qua.
Bài viết này biến những trải nghiệm không mong muốn thành năm khuôn khổ toàn diện sẽ nâng cao công việc học máy dựa trên Excel của bạn.
Xử lý ngoại lai là một nghệ thuật hơn là khoa học, và việc loại bỏ quá sớm có thể loại bỏ các giá trị cực đoan hợp lệ mang thông tin quan trọng. Trong một trường hợp, tất cả các giá trị tài sản nhà ở trên phân vị thứ 95 đã bị loại bỏ bằng cách sử dụng phép tính IQR đơn giản, với giả định rằng chúng là lỗi. Phân tích sau đó đã tiết lộ việc loại bỏ các tài sản có giá trị cực cao hợp lệ, một phân khúc liên quan đến các khoản vay lớn được phê duyệt.
Bài học: Sử dụng nhiều phương pháp phát hiện và xem xét thủ công trước khi loại bỏ. Tạo một khuôn khổ phát hiện ngoại lai toàn diện.
Trong một bảng tính mới bên cạnh dữ liệu chính, tạo các cột phát hiện:
=IF(A2 > QUARTILE.INC($A$2:$A$4270,3) + 1.5*(QUARTILE.INC($A$2:$A$4270,3)-QUARTILE.INC($A$2:$A$4270,1)), "Outlier_IQR", "Normal")=IF(ABS(A2-AVERAGE($A$2:$A$4270)) > 3*STDEV($A$2:$A$4270), "Outlier_3SD", "Normal")=IF(A2 > PERCENTILE.INC($A$2:$A$4270,0.99), "Outlier_P99", "Normal")=IF(COUNTIF(B2:D2,"Outlier*")>=2, "INVESTIGATE", "OK")Cách tiếp cận đa phương pháp này đã tiết lộ các mẫu trong dữ liệu khoản vay của tôi:
Cột "Xem xét thủ công" rất quan trọng. Đối với mỗi quan sát được gắn cờ, hãy ghi lại các phát hiện như: "Tài sản xa xỉ hợp pháp, đã được xác minh đối chiếu với hồ sơ công khai" hoặc "Có khả năng là lỗi nhập liệu, giá trị vượt quá mức tối đa thị trường 10 lần."
Ít có trải nghiệm nào bực bội hơn việc trình bày kết quả mô hình xuất sắc, rồi sau đó không thể tái tạo lại những con số chính xác đó khi chuẩn bị báo cáo cuối cùng. Kịch bản này xảy ra với một mô hình cây phân loại: Độ chính xác xác thực của một ngày là 97.3%, nhưng ngày hôm sau lại là 96.8%. Sự khác biệt có vẻ nhỏ, nhưng nó làm suy yếu độ tin cậy. Khiến khán giả tự hỏi con số nào là thật và phân tích này đáng tin cậy đến mức nào.
Bài học: Thủ phạm là việc phân vùng ngẫu nhiên mà không có một hạt cố định. Hầu hết các thuật toán học máy đều liên quan đến tính ngẫu nhiên ở một giai đoạn nào đó.
XLMiner sử dụng các quy trình ngẫu nhiên để phân vùng dữ liệu. Chạy cùng một mô hình hai lần với các tham số giống hệt nhau sẽ cho kết quả hơi khác nhau vì việc phân chia huấn luyện/xác thực khác nhau mỗi lần.
Giải pháp rất đơn giản nhưng không hiển nhiên. Khi sử dụng chức năng phân vùng của XLMiner (tìm thấy trong hầu hết các hộp thoại mô hình):
Bây giờ, mỗi khi mô hình được chạy với seed này:
Dưới đây là một ví dụ từ bộ dữ liệu phê duyệt khoản vay mà không có seed (ba lần chạy hồi quy logistic giống hệt nhau):
Và với seed=12345 (ba lần chạy hồi quy logistic giống hệt nhau):
Sự khác biệt này có ý nghĩa rất lớn đối với độ tin cậy. Khi được giao nhiệm vụ tái tạo phân tích, điều đó có thể được thực hiện một cách tự tin, biết rằng các con số sẽ khớp nhau.
Lưu ý quan trọng: Seed kiểm soát tính ngẫu nhiên trong việc phân vùng và khởi tạo, nhưng nó không làm cho phân tích miễn nhiễm với các thay đổi khác. Nếu dữ liệu được sửa đổi (thêm quan sát, thay đổi phép biến đổi) hoặc các tham số mô hình được điều chỉnh, kết quả vẫn sẽ khác, như lẽ tự nhiên.
Liên quan đến khả năng tái tạo là chiến lược phân vùng. Cài đặt mặc định của XLMiner tạo ra một phân chia huấn luyện/xác thực 60/40. Điều này có vẻ hợp lý cho đến khi câu hỏi đặt ra: tập kiểm tra ở đâu?
Một lỗi phổ biến là xây dựng một mạng nơ-ron, điều chỉnh nó dựa trên hiệu suất xác thực, sau đó báo cáo các chỉ số xác thực đó làm kết quả cuối cùng.
Bài học: Không có tập kiểm tra riêng biệt, việc tối ưu hóa xảy ra trực tiếp trên dữ liệu được báo cáo, làm tăng ước tính hiệu suất. Chiến lược phân vùng đúng đắn sử dụng ba tập.
1. Tập huấn luyện (50% dữ liệu)
2. Tập xác thực (30% dữ liệu)
3. Tập kiểm tra (20% dữ liệu)
Quy tắc quan trọng: Không bao giờ lặp lại trên hiệu suất của tập kiểm tra. Ngay khi một mô hình được chọn vì "nó hoạt động tốt hơn trên tập kiểm tra," tập kiểm tra đó trở thành một tập xác thực thứ hai và các ước tính hiệu suất trở nên thiên vị.
Đây là quy trình làm việc của tôi hiện tại:
Dưới đây là một ví dụ từ dự án phê duyệt khoản vay:
| Phiên bản mô hình | Độ chính xác huấn luyện | Độ chính xác xác thực | Độ chính xác kiểm tra | Đã chọn? |
|---|---|---|---|---|
| Hồi quy Logistic (tất cả biến) | 90.6% | 89.2% | Chưa chấm điểm | Không |
| Hồi quy Logistic (từng bước) | 91.2% | 92.1% | Chưa chấm điểm | Không |
| Cây phân loại (độ sâu=7) | 98.5% | 97.3% | Chưa chấm điểm | Có |
| Cây phân loại (độ sâu=5) | 96.8% | 96.9% | Chưa chấm điểm | Không |
| Mạng nơ-ron (7 nút) | 92.3% | 90.1% | Chưa chấm điểm | Không |
Sau khi chọn Cây phân loại (độ sâu=7) dựa trên hiệu suất xác thực, tập kiểm tra đã được chấm điểm chính xác một lần: độ chính xác 97.4%. Độ chính xác kiểm tra này đại diện cho hiệu suất sản xuất mong đợi.
Vấn đề: Cái nhìn ban đầu về kết quả cây phân loại từ báo cáo dự án có vẻ hứa hẹn.
Hiệu suất dữ liệu huấn luyện:
Mô hình có vẻ thành công cho đến nay cho đến khi sự chú ý chuyển sang kết quả xác thực.
Hiệu suất dữ liệu xác thực:
Sự khác biệt có vẻ nhỏ, chỉ 1.18% độ chính xác. Nhưng việc xác định liệu khoảng cách này có tạo thành một vấn đề hay không đòi hỏi một khuôn khổ có hệ thống.
Bài học: Điều quan trọng là phải hiểu khi nào mô hình ghi nhớ thay vì học.
Giải pháp thực tế: Tạo một công cụ giám sát overfitting. Xây dựng một bảng so sánh đơn giản nhưng có hệ thống giúp overfitting trở nên rõ ràng.
Bước 1: Tạo khuôn khổ so sánh
Dưới đây là so sánh hiệu suất mô hình trong bảng tính "Overfitting_Monitor":
| Chỉ số | Huấn luyện | Xác thực | Khoảng cách | Khoảng cách % | Trạng thái |
|---|---|---|---|---|---|
| Độ chính xác | 98.45% | 97.27% | 1.18% | 1.20% | ✓ Tốt |
| Độ chính xác (Precision) | 99.00% | 98.00% | 1.00% | 1.01% | ✓ Tốt |
| Độ phủ | 96.27% | 94.40% | 1.87% | 1.94% | ✓ Tốt |
| Điểm F1 | 98.76% | 97.27% | 1.49% | 1.51% | ✓ Tốt |
| Độ đặc hiệu | 96.56% | 92.74% | 3.82% | 4.06% | ? Theo dõi |
Và đây là các quy tắc diễn giải:
Và đây là phân tích chi tiết:
Bước 2: Thêm các công thức tính toán
Ô: Khoảng cách (cho Độ chính xác)=[@Training] - [@Validation]
Ô: Khoảng cách % (cho Độ chính xác)=([@Training] - [@Validation]) / [@Training]
Ô: Trạng thái (cho Độ chính xác)
=IF([@[Gap %]]<0.03, "✓ Good",
IF([@[Gap %]]<0.05, "? Watch",
IF([@[Gap %]]<0.10, "⚠ Concerning", "✗ Problem")))Bước 3: Tạo biểu đồ overfitting trực quan
Xây dựng biểu đồ cột so sánh huấn luyện với xác thực cho từng chỉ số. Điều này giúp các mẫu trở nên dễ nhìn ngay lập tức:

Khi các thanh gần nhau, mô hình khái quát hóa tốt. Khi các thanh huấn luyện dài hơn nhiều so với các thanh xác thực, có hiện tượng overfitting.
So sánh giữa các mô hình khác nhau
Giá trị thực sự đến từ việc so sánh các mẫu overfitting giữa các tùy chọn mô hình. Dưới đây là so sánh cho bảng tính "Model_Overfitting_Comparison":
| Mô hình | Độ chính xác huấn luyện | Độ chính xác xác thực | Khoảng cách | Rủi ro Overfitting |
|---|---|---|---|---|
| Hồi quy Logistic | 91.2% | 92.1% | -0.9% | Thấp (khoảng cách âm) |
| Cây phân loại | 98.5% | 97.3% | 1.2% | Thấp |
| Mạng nơ-ron (5 nút) | 90.7% | 89.8% | 0.9% | Thấp |
| Mạng nơ-ron (10 nút) | 95.1% | 88.2% | 6.9% | Cao – Loại bỏ cái này |
| Mạng nơ-ron (14 nút) | 99.3% | 85.4% | 13.9% | Rất cao – Loại bỏ cái này |
Giải thích: Mạng nơ-ron với 10+ nút rõ ràng đang bị overfitting. Mặc dù độ chính xác huấn luyện cao (99.3%), độ chính xác xác thực giảm xuống 85.4%. Mô hình đã ghi nhớ các mẫu dữ liệu huấn luyện không khái quát hóa được.
Lựa chọn tốt nhất: Cây phân loại
Dưới đây là một số cách đơn giản để giảm overfitting khi phát hiện:
Lỗi nhập liệu là những kẻ giết người thầm lặng của các dự án học máy. Một lỗi đánh máy duy nhất, chẳng hạn như "gradute" thay vì "graduate", sẽ tạo ra một danh mục thứ ba trong cái lẽ ra phải là một biến nhị phân. Mô hình hiện có một giá trị đặc trưng không mong muốn mà nó chưa bao giờ thấy trong quá trình huấn luyện, có khả năng gây ra lỗi trong quá trình triển khai hoặc tệ hơn là âm thầm tạo ra các dự đoán không chính xác.
Cách phòng ngừa: Tính năng xác thực dữ liệu của Excel. Dưới đây là giao thức triển khai cho các biến phân loại:
Trong một bảng tính ẩn (đặt tên là "Validation_Lists"), tạo danh sách các giá trị hợp lệ:
Trong bảng tính nhập liệu:
Giờ đây, không thể nhập các giá trị không hợp lệ. Người dùng thấy một danh sách thả xuống với các lựa chọn hợp lệ, loại bỏ hoàn toàn lỗi đánh máy.
Đối với các biến số với các phạm vi đã biết, áp dụng xác thực tương tự để ngăn chặn các giá trị không thể:
Chọn cột, áp dụng xác thực dữ liệu, đặt:
Dưới đây là tóm tắt các bài học được trình bày trong bài viết.
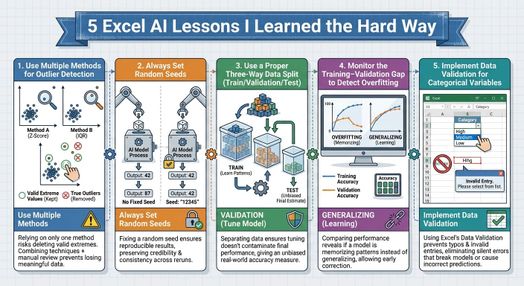
Năm thực hành trong bài viết này — phát hiện ngoại lai đa phương pháp, đặt hạt ngẫu nhiên, phân vùng dữ liệu ba phần, giám sát khoảng cách huấn luyện-xác thực và triển khai xác thực dữ liệu — có chung một điểm: tất cả đều đơn giản để thực hiện nhưng lại rất tai hại nếu bỏ qua.
Không thực hành nào trong số này đòi hỏi kiến thức thống kê nâng cao hay lập trình phức tạp. Chúng không yêu cầu phần mềm bổ sung hay công cụ đắt tiền. Excel XLMiner là một công cụ mạnh mẽ cho học máy dễ tiếp cận.
Rachel Kuznetsov có bằng Thạc sĩ Phân tích Kinh doanh và thích giải quyết các bài toán dữ liệu phức tạp cũng như tìm kiếm những thử thách mới. Cô ấy cam kết làm cho các khái niệm khoa học dữ liệu phức tạp dễ hiểu hơn và đang khám phá nhiều cách AI tác động đến cuộc sống của chúng ta. Trong hành trình không ngừng học hỏi và phát triển của mình, cô ấy ghi lại hành trình của mình để những người khác có thể học hỏi cùng cô ấy. Bạn có thể tìm thấy cô ấy trên LinkedIn.






