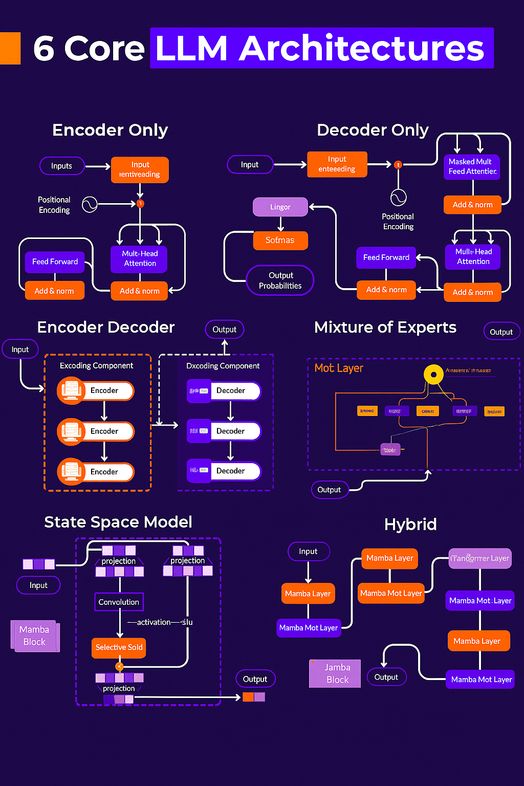
Không phải tất cả các mô hình ngôn ngữ lớn (LLM) đều được tạo ra như nhau. Và nếu bạn không biết chúng được xây dựng như thế nào, bạn sẽ không bao giờ biết khi nào nên sử dụng chúng.
Một số mô hình rất giỏi trong việc hiểu văn bản, một số được tối ưu hóa để tạo ra các đầu ra dài, và một số khác mở rộng quy mô tốt hơn với chi phí tính toán thấp hơn.
Dưới đây là 6 kiến trúc LLM quan trọng nhất cần biết trong năm 2025, giúp bạn lựa chọn mô hình tốt hơn, thiết kế hệ thống thông minh hơn và tránh những sai lầm tốn kém.
1. Encoder-Only (Autoencoders)
Cách hoạt động: Sử dụng bộ mã hóa transformer hai chiều để hiểu toàn bộ ngữ cảnh của văn bản đầu vào.
Cách huấn luyện: Với mô hình ngôn ngữ mặt nạ (Masked Language Modeling - MLM) — ngẫu nhiên ẩn các từ và dự đoán chúng.
Tuyệt vời cho: Hiểu văn bản, nhúng (embeddings), phân loại.
Ví dụ: BERT, RoBERTa.
2. Decoder-Only (Autoregressive)
Cách hoạt động: Sử dụng bộ giải mã một chiều để dự đoán token tiếp theo trong một chuỗi.
Cách huấn luyện: Với mô hình ngôn ngữ nhân quả (Causal Language Modeling - CLM) — dự đoán từ tiếp theo dựa trên các từ trước đó.
Tuyệt vời cho: Tạo văn bản, gợi ý vài shot (few-shot prompting), tác nhân (agents).
Ví dụ: GPT-4, LLaMA 3, Claude.
3. Encoder-Decoder (Seq2Seq)
Cách hoạt động: Mã hóa đầu vào, sau đó giải mã một phản hồi, giống như dịch một câu này sang một câu khác.
Cách huấn luyện: Với làm hỏng khoảng (span corruption) hoặc các mục tiêu sequence-to-sequence.
Tuyệt vời cho: Dịch thuật, tóm tắt, các tác vụ đầu vào-đầu ra.
Ví dụ: T5, BART.
4. Mixture of Experts (MoE)
Cách hoạt động: Chỉ một vài "chuyên gia" chuyên biệt được kích hoạt cho mỗi đầu vào, giảm tổng chi phí tính toán.
Cách huấn luyện: Với các mạng cổng (gating networks) định tuyến đầu vào đến các mô hình con cụ thể.
Tuyệt vời cho: Mở rộng quy mô các mô hình lớn một cách hiệu quả.
Ví dụ: DeepSeek-V2, LLaMA 4.
5. State Space Models (SSM)
Cách hoạt động: Thay thế cơ chế chú ý (attention) bằng các chuyển đổi dựa trên trạng thái — xử lý các chuỗi tuyến tính theo thời gian.
Cách huấn luyện: Với động lực học không gian trạng thái (state-space dynamics) thay vì chú ý từng token.
Tuyệt vời cho: Các tài liệu dài, suy luận nhanh hơn (faster inference), hiệu quả bộ nhớ.
Ví dụ: Mamba.
6. Hybrid Architectures
Cách hoạt động: Kết hợp các thành phần từ nhiều kiến trúc — ví dụ, Transformers + SSMs.
Cách huấn luyện: Với các mục tiêu hỗn hợp tùy thuộc vào các lớp/module.
Tuyệt vời cho: Cân bằng tốc độ, quy mô và độ chính xác.
Ví dụ: Jamba (kết hợp Transformer + Mamba).
Mỗi kiến trúc giải quyết một vấn đề khác nhau.
Việc biết bạn đang làm việc với kiến trúc nào sẽ giúp bạn: ✔️ Chọn mô hình tốt hơn ✔️ Thiết kế hệ thống thông minh hơn ✔️ Tránh những sai lầm tốn kém