Công nghệ - 21/05/2025 03:04:45
Xin chào các anh em coder và những tín đồ công nghệ! Hôm nay mình sẽ lôi “cái chatbot AI” của chúng ta ra ánh sáng, phân tích vì sao nó đôi khi chậm như rùa bò, dù được tích hợp cả RAG (Retrieval-Augmented Generation), phân tích nghiệp vụ, và đủ thứ “hàng nóng” khác.
Không chỉ dừng ở lý thuyết, mình sẽ đưa ra vài đoạn code “huyền thoại” khiến AI “hờn dỗi”, lại còn khóc rống và cách khắc phục chúng.
Một chatbot AI hiện đại không chỉ là một mô hình ngôn ngữ (LLM) đơn thuần. Nó còn phân tích dữ liệu nghiệp vụ, truy vấn database, tích hợp RAG, gọi API, và đôi khi còn “tự suy nghĩ” (như Grok 3 với DeepSearch mode).

Nhưng chính sự phức tạp này lại mở ra cánh cửa cho những vấn đề về hiệu suất. Hãy cùng điểm qua các “thủ phạm” chính:
1. Phía nghiệp vụ: Khi AI bị “nhồi” quá nhiêu việc
- Quá tải yêu cầu nghiệp vụ: Chatbot của bạn không chỉ trả lời “Hello, how can I help?” mà còn phải phân tích dữ liệu doanh thu, truy vấn kho hàng, hoặc sinh báo cáo tài chính. Nếu pipeline xử lý nghiệp vụ không được tối ưu, AI sẽ tốn thời gian chờ đợi từng bước. Ví dụ đơn giản: Một truy vấn SQL phức tạp, ở một bảng lớn có thể mất vài giây đến vài chục giây để trả về kết quả từ database.
- RAG không hiệu quả: RAG (Retrieval-Augmented Generation) là kỹ thuật “xịn sò” giúp AI lấy thông tin từ cơ sở tri thức trước khi trả lời. Nhưng nếu cơ sở tri thức quá lớn hoặc không được phân mảnh (chunking) hợp lý, việc tìm kiếm vector sẽ tốn thời gian. Chưa kể, nếu embedding model không tối ưu, việc chuyển đổi câu hỏi thành vector có thể “ngốn” cả đống CPU/GPU.
- Tích hợp API bên thứ ba: Gọi API thời tiết, API thanh toán, hoặc API CRM mà server đối tác chậm hoặc không ổn định? AI của bạn sẽ đứng hình, chờ đợi như kiểu chờ crush trả lời tin nhắn.
- Logic nghiệp vụ phức tạp: Nếu quy trình nghiệp vụ yêu cầu nhiều bước kiểm tra điều kiện (ví dụ: xác thực người dùng, kiểm tra quyền, phân tích dữ liệu), thời gian xử lý sẽ tăng lên đáng kể.
2. Phía Code: Khi anh em Dev “Vô Tình” làm AI khóc thầm
- Quản lý tài nguyên kém: Code không tối ưu, không sử dụng async/await đúng cách trong .NET, hoặc quên giải phóng tài nguyên (như connection database) có thể khiến chatbot bị nghẽn.
- Xử lý bất đồng bộ nửa vời: Gọi API hoặc truy vấn database mà không dùng async/await? Bạn đang buộc AI phải chờ từng tác vụ hoàn thành, như kiểu xếp hàng mua matcha latte giờ cao điểm - sáng đưa cháu đi học phải đứng chờ nên hơi bức xúc !!!.
- Thiếu caching: Nếu mỗi câu hỏi của người dùng đều kích hoạt lại toàn bộ pipeline RAG hoặc truy vấn database, server của bạn sẽ “toát mồ hôi”.
- Lỗi cấu hình mô hình AI: Chọn sai mô hình AI (quá lớn hoặc quá nhỏ), không tận dụng GPU, hoặc cấu hình inference không tối ưu cũng là nguyên nhân khiến AI “hụt hơi”.
Để minh họa, mình sẽ chia sẻ vài đoạn code .NET “đỉnh cao” mà mình từng gặp (hay thực ra là mình từng viết trong những ngày mệt mỏi). Đừng phán xét mình nhé, ai mà chẳng có lúc “trượt tay, trượt chân” :D

Vấn đề: Tất cả các tác vụ (gọi API, truy vấn DB, RAG) đều chạy đồng bộ. Mỗi bước mất 1-2 giây, cộng lại thành 5-6 giây chờ đợi. Người dùng ngồi nhìn màn hình loading mà tưởng mạng 2G quay lại.
Cách sửa: dùng Async/await

Kết quả: Các tác vụ chạy song song, giảm thời gian chờ từ 6 giây xuống còn 2 giây (tùy thuộc vào tác vụ lâu nhất). Async/await là “cứu tinh” của bạn! Hoàn hảo :))

Vấn đề: Mỗi khi người dùng hỏi cùng một câu (hoặc câu tương tự), hệ thống lại embedding và tìm kiếm từ đầu. Cơ sở tri thức 10GB mà cứ tìm kiếm liên tục thì CPU khóc thét!
Cách sửa:

Kết quả: Caching giảm tải cho hệ thống, đặc biệt với các câu hỏi phổ biến. Thời gian phản hồi giảm từ 1.5s xuống còn vài millisecond nếu đã có trong cache. - cheating :D

Vấn đề: Query SQL “khủng” không tối ưu, không có index trên các cột CustomerId, ProductId. Database phải scan toàn bộ bảng, mất vài giây mỗi lần chạy.
Cách sửa:

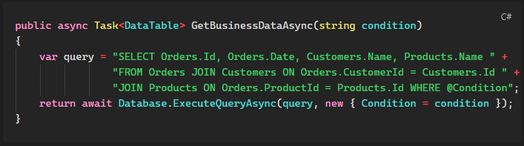
Kết quả: Index và query tối ưu giảm thời gian truy vấn từ 20 giây xuống dưới 200ms - mình đoán vậy thôi nhé
Gemini tự hào với 1-2 triệu tokens, Grok 3 với khả năng xử lý cả tá token. Chúng ta thử nhồi nhét toàn bộ object dữ liệu khổng lồ vào prompt xem sao. Tưởng rằng "càng nhiều thông tin càng tốt", nhưng hóa ra lại khiến LLM "ngáp dài" và server thì "toát mồ hôi"!

Vấn đề: BigFatObject chứa cả lịch sử giao dịch, thông tin khách hàng, và cả log hệ thống từ thời "khai thiên lập địa". Gửi nguyên cục JSON này cho LLM không chỉ tốn thời gian xử lý mà còn làm tăng chi phí inference, chưa kể LLM có thể bị "lạc trôi" vì context quá dài và không tập trung.
Cách sửa: Lọc dữ liệu trước khi gửi!
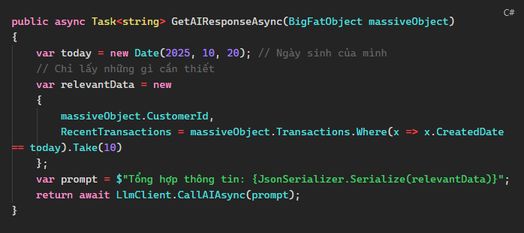
Kết quả: Giảm kích thước context từ 10MB xuống vài KB, thời gian xử lý nhanh hơn, LLM "vui vẻ" hơn, và ví tiền của bạn cũng bớt "đau". Hãy nhớ: LLM thông minh, nhưng đừng bắt nó đọc cả "tự truyện" của dữ liệu!
NOTE: những đoạn code ví dụ trên mình draft để làm ví dụ trong lúc buồn ngủ. Có thể chạy hoặc không chạy, bạn thông cảm nhé :D
Để chatbot AI của bạn “chạy nhanh như gió”, cần kết hợp tối ưu cả nghiệp vụ lẫn code:
1. Tối ưu RAG:
Chatbot AI chậm đầu tiên là lỗi do nó, và cũng không phải lỗi của nó. Thường là do chúng ta “muốn thử thách server” hay “vô tình” giao quá nhiều việc hoặc viết code kiểu... xin lỗi ông trời. Bằng cách tối ưu pipeline nghiệp vụ, caching thông minh, và viết code bất đồng bộ, bạn sẽ giúp AI trả lời nhanh như chớp, khiến người dùng chỉ muốn “yêu thêm lần nữa”.
Hy vọng bài viết này giúp anh em coder có thêm góc nhìn và chút tiếng cười khi debug những đoạn code “huyền thoại”.
Nếu bạn có câu chuyện nào về chatbot AI “lầy lội”, coder "chày cối" hoặc mẹo tối ưu hay ho, comment bên dưới để mình học hỏi nhé!
Nguồn tham khảo
/Son Do - I share real-world lessons, team building & developer growth.
#AIChatbot #PerformanceMatters #RAG #DotNet #AsyncAwait #CachingIsKing #CleanCode #LLMOptimization #DeveloperLife #AIPipeline #wecommit100xshare #1percentbetter